
The Ingestor and the Harmoniser are two key components of the BIGG project technical architecture. Their role is to collect and make comparable data from different sources over internal BIGG standard data model.
In the BIGG project they are designed to be:
- Efficient: engaging as less computational resources as possible.
- Scalable and elastic: allowing more instances to run in the system on different nodes to (possibly linearly) increase the throughput; making easy to add, remove or move instances across the system.
- Robust: coping with errors and with erroneous inputs without compromising the operation of the system.
The Ingestor is responsible to receive inbound transmissions of building data (energy consumption or production, occupancy, energy efficiency measures, etc.) to route this data internally in the system.
In the BIGG project Ingestors are designed with the following characteristics:
- Unsolicited: actively discovering and querying devices to ingest data through configurable task
- Solicited: passively waiting for external incoming API calls to ingest data
- Responsive: responding in a timely manner
- Generic and durable: managing incoming transmission in generic way, without claiming to understand what’s the nature or the content of the transmission
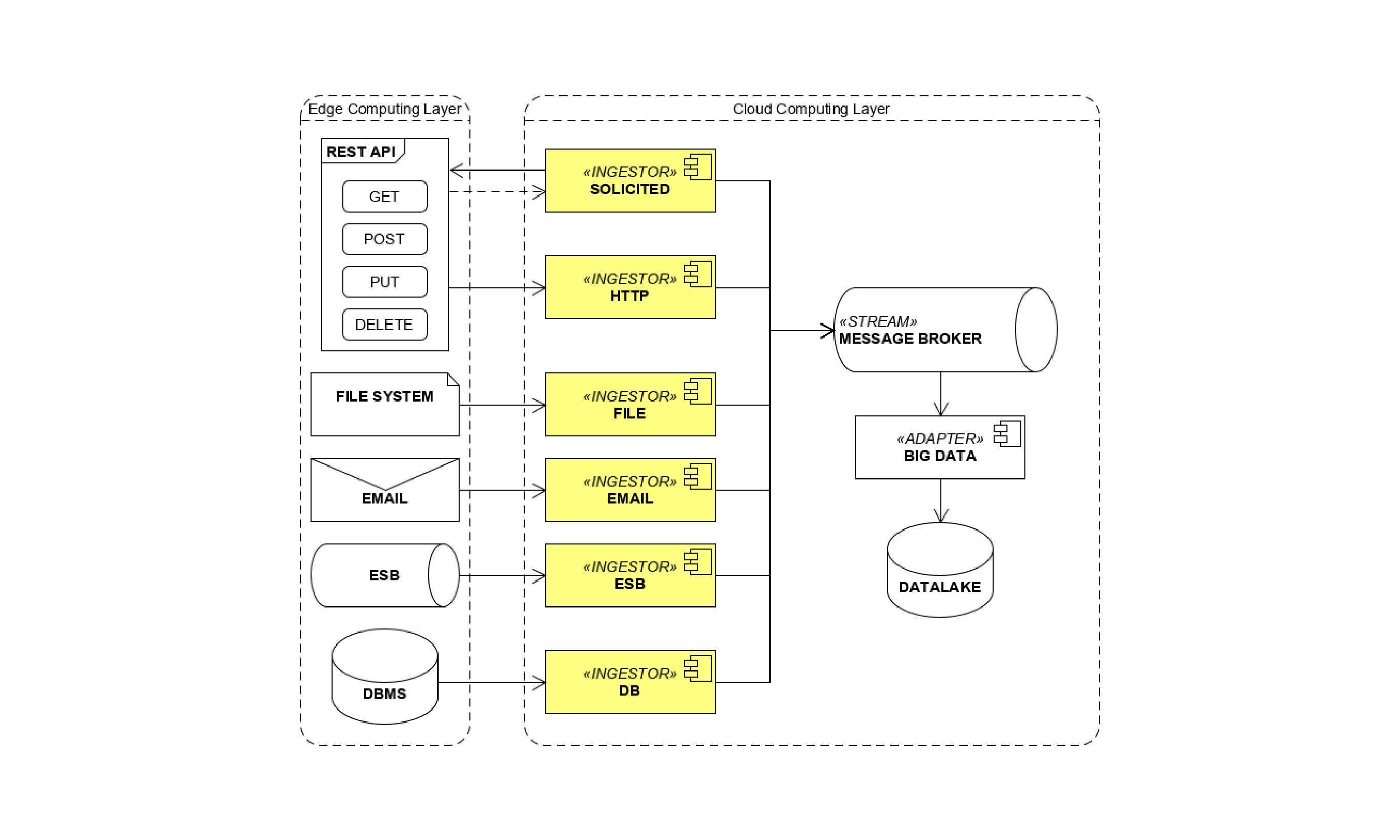
Due to all the different source protocols and formats (API’s, files, emails, other ESB, databases, etc.), the ingestion services are the frontend of the system designed and implemented to collect data in a generic and agnostic way. The content of the message is not manipulated but enriched with a set of metadata describing its origin, protocol, format, incoming timestamp, etc. Once this enriched message on the appropriate message broker’s topic is produced, the “adapter” component will consume it and will save it as is in the data lake repository.
The Harmoniser operate in the system as a microservice based on the “Processor” pattern. It is responsible for translating all incoming messages to a common message format so that any other component of the system can benefit of any data message in a fast and standardized way.
In the BIGG project Harmonisers are designed with the following characteristics:
- Responsive: minimizing the latency from the incoming message to the time the message has being stored and handled by the system.
- Maintainable and extensible: allowing to respond quickly to the market that asks for new formats of data message to be supported by the system.
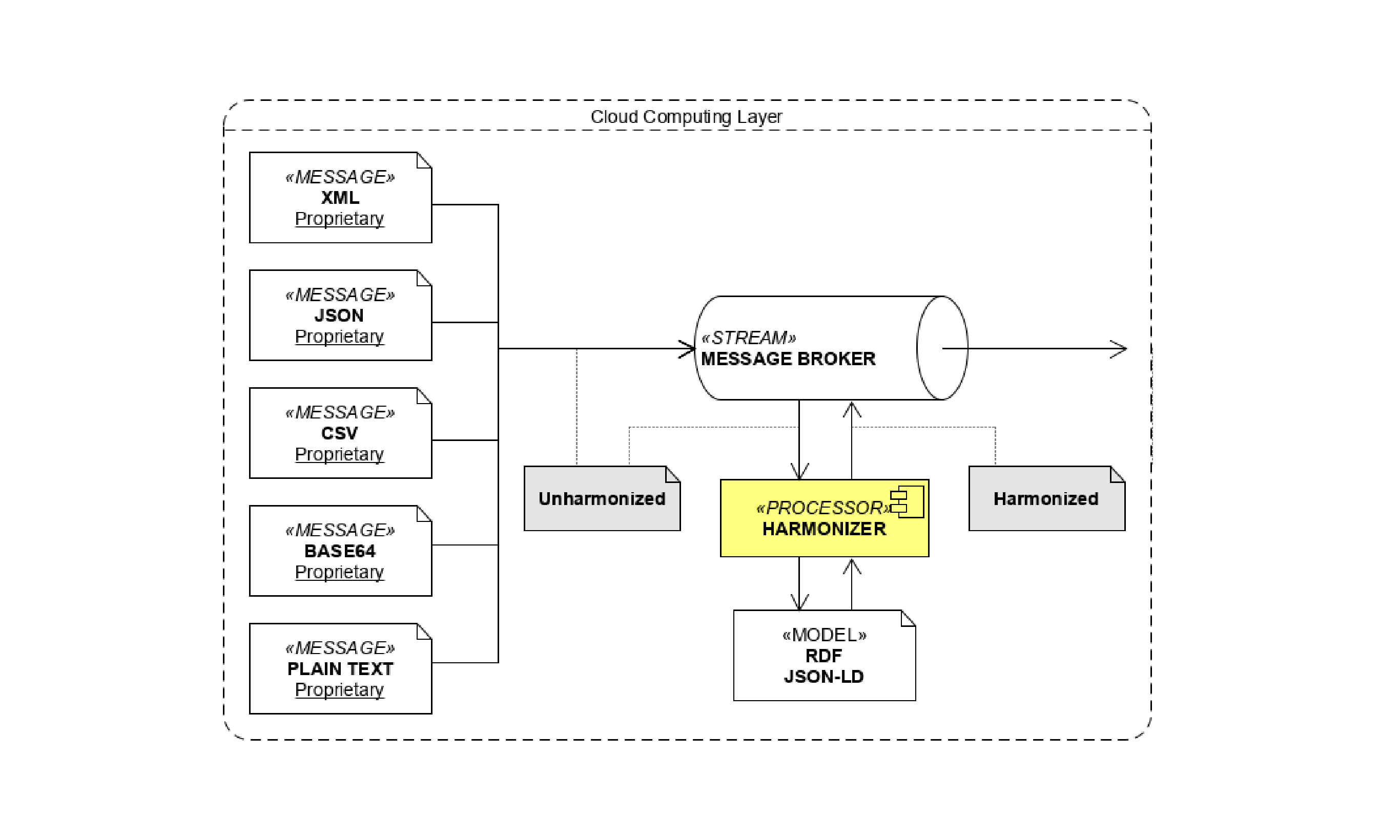
The raw messages ingested and stored into the datalake will have different contents expressed in different formats: XML, JSON, CSV, Base64, plain test, etc. The Harmoniser component has the specific and very important role to translate all these different message formats into a standardized model so that all the subsequent services in the flow will be able to handle their different contents using a “common language” expressed in RDF for the static informations (buildings, catastrial data, devices, etc.) and in JSON-LD for the dynamic informations like the timeseries.
Today Ingestors and Harmonisers are actively used in BIGG use cases to feed the AI toolbox with BIGG harmonized data.
